Test Gitaly Cluster and Praefect to evaluate adding to Reference Architectures
Gitaly Cluster (and Praefect) are close to GA and as such the Reference Architectures need to be updated and tested along with Docs updated.
As part of the performance tests we should also do these workflow tests - https://gitlab.com/gitlab-org/quality/team-tasks/-/issues/451#ha-workflow-tests.
Designs
Is blocked by
Relates to
- gitlab-org/quality/performance #23113.05

- gitaly #333713.8

- omnibus-gitlab #591914.7
Activity

@grantyoung Was your plan for this issue to update the Reference Architectures to use Gitaly Cluster (it's been renamed from HA gitlab-org/gitlab!31824), and to run the existing performance tests. Or to add new tests as well?
I ask because we have several new tests we also need to perform, some of which will involve generating load and measuring performance: https://gitlab.com/gitlab-org/quality/team-tasks/-/issues/451. But I assume those weren't the tests referred to in this issue, right? If not, I'll probably still need your help when I get time to work on them.

Unfortunately, I haven't had a chance yet to progress further with performance#231
marked this issue as related to performance#231
Looks like indeed it is ready to go with decent docs as well. Will start this ASAP as it's effectively generally available. Will go through the docs as well as part of this process and provide any feedback.
cc @zj-gitlab
Gitaly Cluster Scaling
One aspect that we need to consider here is performance scaling. When we first set up the reference architectures the largest, 50k, simply couldn't handle the load with one large Gitaly node. It was then clear that this wasn't realistic and we needed more nodes which sorted the issue.
With Cluster it's a failover system meaning the other shards in the cluster aren't used proper until master fails. As such we'll likely need multiple clusters for the larger environments (thinking 25k and 50k, possibly only 50k that I think was the only one to falter at it's scale). Praefect looks to handle multiple clusters fine though so this isn't a problem outside of added costs.
At the moment without testing anything (yet) but based on testing in the past I suspect only 50k will truly need this (and then could only need 2) and the others can be single clusters with vertical scaling. Will update here when I know more.
Edited by Grant YoungActually I just noticed this feature looks to have made it into
13.0- gitlab-org/gitaly#2650This would suggest reads are distributed across the Gitaly nodes? If this is the case it may remove the need for multiple clusters...
Edited by Grant Young
Praefect Internal Load Balancer
Praefect will need it's own internal load balancer, much like we already do with PgBouncer.
For easiness sake we could just make the same same LB we use for pgbouncer but this feels like it would be very unwise as all repo and sql calls will be going through the one LB. Will need to retool the builder to have 2 internal LBs.
@zj-gitlab Can you give me a sanity check on the above? I heavily assume that praefect's load balancer should be exclusive.

@grantyoung On GitLab.com we did create a new LB for Praefect, also because its relatively easy to set up.
For easiness sake we could just make the same same LB we use for pgbouncer but this feels like it would be very unwise as all repo and sql calls will be going through the one LB.
Yes, you could. As long as the rules don't mix the traffic, but that goes without saying.

mentioned in issue performance#246
marked this issue as related to performance#246
Docs \ Install Notes
Below are just my notes \ ramblings on the docs \ install as I go through them.
Disabling all services on the Praefect node
I actually have a much bigger list of disables. I inherited this list from some previous support config. Unsure if they’re actually all needed?
git_data_dirsneeding the default entry on GitLab RailsTotally appreciate this is an overhang of GitLab and that we have to work with it but I did have some confusion around this and why it was needed and I suspect customers could as well.
Prometheus Config
I was wondering if with Consul this would be picked up automatically but it doesn’t for Praefect. PgBouncer is the same but it has an issue open. Is there plans to do the same for Praefect? Also the docs specify to do manual config for Gitaly as well but this isn’t required when consul is deployed.
The config is currently under the GitLab section but this may should be separated out into it’s own? For most customers deplying cluster the monitoring node will be separate.
In addition a very small nit pick is for the Gitaly “service” that’s enabled on GitLab rails nodes you’ll also need to specify the prometheus listen address (gitaly['prometheus_listen_addr'] = "0.0.0.0:9236") or it’ll show as localhost in prom and as an error. However a consequence of this on larger installs is a much larger exporter list of essentially unused Gitaly nodes. It may be best to find out if we can disable this (with consul auto discovery).
Postgres for Praefect should be a cluster also
Already discussed but worth adding here is that the docs make it seem like a single node postgres server for praefect is enough when it shouldn’t be.
Step 11 for GitLab Update the Repository storage settings refers to a storage location named praefect incorrectly?
The docs say to set the repository storage to praefect but this isn’t what it’s called if you’ve been following the docs. It should be storage-1?
Example outputs for the two praefect test commands?
The two test commands for praefect to check postgres and gitaly are reachable worked great and were quite helpful. May be good to get show what a passing output looks like though?
Convenience Script for Praefect DB setup?
Any plans for a convenience script or something similar for the Praefect database setup?
Step 10 for Praefect mistake?
To ensure that Praefect has updated its Prometheus listen address, restart Gitaly:
I think that’s meant to say restart Praefect?
Sidekiq Config?
We'll need to call out Sidekiq in the docs and that it will need the same
git_data_dirsconfig as well if it's on separate nodes.Edited by Grant Young- Edited by Grant Young
Performance Test Results
I was able to get Cluster up and running pretty easily thanks to the well written docs! As such I'm starting performance testing to validate the environment setup and then tune.
50k is the environment of choice for this as it's exposed issues in the past with Gitaly that smaller environment's didn't.
Test 1 - 50k, 1 Gitaly Cluster
First test was done with the same specs as given in the 50k Reference Architecture with the following additional notes:
- Praefect specs are set to the same as pgbouncer (
n1-highcpu-2) - Wanted to first test out one Gitaly Cluster for 50k with the same specs as the previous 4 separate nodes. We had multiple gitaly nodes set for 50k to achieve both performance and availability so with the latter now built in it's worth resetting and seeing where the sweet spot is. In addition to this with gitlab-org/gitaly#2650 added a single cluster may now be able to server this architecture.
- Environment is using the same internal load balancer (with higher specs) for convenience.
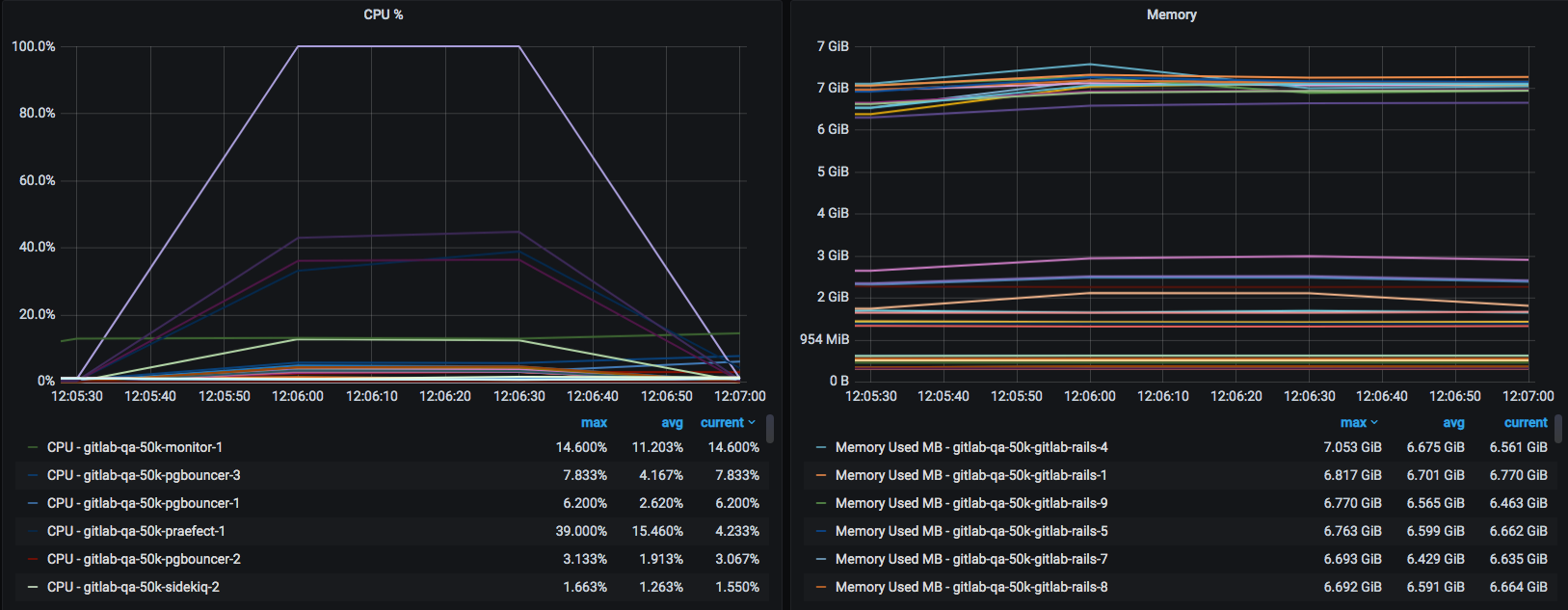
* Environment: 50k * Environment Version: 13.0.0-pre `f45762cdbd6` * Option: 60s_1000rps * Date: 2020-05-21 * Run Time: 1h 7m 49.72s (Start: 10:05:18 UTC, End: 11:13:08 UTC) * GPT Version: v1.3.1 ❯ Overall Results Score: 90.68% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ---------------------------------------------------------|--------|----------------------|------------|-----------------------|----------------|------------------ api_v4_groups | 1000/s | 980.48/s (>800.00/s) | 32.32ms | 34.36ms (<1500ms) | 100.00% (>95%) | Passed api_v4_groups_group | 1000/s | 974.95/s (>800.00/s) | 112.25ms | 134.23ms (<1500ms) | 100.00% (>95%) | Passed api_v4_groups_projects | 1000/s | 976.67/s (>800.00/s) | 96.98ms | 113.77ms (<2000ms) | 100.00% (>95%) | Passed api_v4_projects_deploy_keys | 1000/s | 980.23/s (>800.00/s) | 38.18ms | 40.39ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_issues | 1000/s | 911.35/s (>720.00/s) | 946.74ms | 1208.04ms (<2000ms) | 100.00% (>95%) | Passed api_v4_projects_issues_issue | 1000/s | 877.87/s (>800.00/s) | 993.31ms | 1571.42ms (<3000ms) | 100.00% (>95%) | Passed api_v4_projects_languages | 1000/s | 979.88/s (>800.00/s) | 34.80ms | 36.60ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests | 1000/s | 888.03/s (>480.00/s) | 1000.10ms | 1242.17ms (<2000ms) | 99.95% (>95%) | Passed api_v4_projects_merge_requests_merge_request | 1000/s | 975.18/s (>800.00/s) | 92.58ms | 103.01ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_changes | 1000/s | 976.73/s (>800.00/s) | 90.89ms | 99.35ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_commits | 1000/s | 978.36/s (>800.00/s) | 57.38ms | 61.90ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_discussions | 1000/s | 969.35/s (>800.00/s) | 209.89ms | 308.11ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_pagination_keyset | 1000/s | 970.82/s (>160.00/s) | 142.54ms | 170.00ms (<7500ms) | 100.00% (>95%) | Passed api_v4_projects_pagination_offset | 1000/s | 971.23/s (>160.00/s) | 234.82ms | 548.34ms (<7500ms) | 100.00% (>95%) | Passed api_v4_projects_project | 1000/s | 975.37/s (>800.00/s) | 90.52ms | 99.63ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_pipelines | 1000/s | 979.28/s (>800.00/s) | 47.23ms | 50.96ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_search_blobs | 1000/s | 485.58/s (>80.00/s) | 1860.29ms | 2375.46ms (<15000ms) | 100.00% (>95%) | Passed api_v4_projects_project_services | 1000/s | 980.1/s (>800.00/s) | 36.58ms | 38.56ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_branches | 1000/s | 88.53/s (>160.00/s) | 9396.99ms | 10933.04ms (<7500ms) | 100.00% (>95%) | FAILED²³ api_v4_projects_repository_branches_branch | 1000/s | 978.17/s (>800.00/s) | 63.00ms | 74.67ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits | 1000/s | 978.3/s (>800.00/s) | 59.09ms | 64.66ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_sha | 1000/s | 755.2/s (>800.00/s) | 1098.28ms | 1424.74ms (<500ms) | 100.00% (>95%) | FAILED²³ api_v4_projects_repository_commits_sha_diff | 1000/s | 978.92/s (>800.00/s) | 56.26ms | 64.34ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_compare_commits | 1000/s | 246.85/s (>800.00/s) | 3583.03ms | 4235.01ms (<500ms) | 100.00% (>95%) | FAILED²³ api_v4_projects_repository_files_file | 1000/s | 517.1/s (>800.00/s) | 1707.66ms | 2895.00ms (<500ms) | 99.90% (>95%) | FAILED²³ api_v4_projects_repository_files_file_blame | 1000/s | 36.7/s (>8.00/s) | 18642.88ms | 25437.98ms (<35000ms) | 100.00% (>95%) | Passed api_v4_projects_repository_files_file_raw | 1000/s | 346.43/s (>800.00/s) | 2581.12ms | 4106.05ms (<500ms) | 100.00% (>95%) | FAILED²³ api_v4_projects_repository_tree | 1000/s | 904.22/s (>800.00/s) | 787.12ms | 1186.13ms (<500ms) | 100.00% (>95%) | FAILED²³ api_v4_search_global | 1000/s | 886.32/s (>240.00/s) | 1994.38ms | 5672.23ms (<25000ms) | 45.78% (>9.5%) | Passed api_v4_search_groups | 1000/s | 731.95/s (>240.00/s) | 2572.93ms | 7432.22ms (<25000ms) | 43.62% (>9.5%) | Passed api_v4_search_projects | 1000/s | 607.22/s (>240.00/s) | 2996.96ms | 8490.03ms (<25000ms) | 49.41% (>9.5%) | Passed api_v4_user | 1000/s | 980.1/s (>800.00/s) | 28.87ms | 30.71ms (<500ms) | 100.00% (>95%) | Passed api_v4_users | 1000/s | 980.18/s (>800.00/s) | 34.47ms | 36.37ms (<500ms) | 100.00% (>95%) | Passed git_ls_remote | 100/s | 97.95/s (>80.00/s) | 43.80ms | 44.87ms (<500ms) | 100.00% (>95%) | Passed git_pull | 100/s | 97.97/s (>80.00/s) | 51.16ms | 61.57ms (<500ms) | 100.00% (>95%) | Passed web_group | 100/s | 95.63/s (>80.00/s) | 88.94ms | 103.79ms (<500ms) | 100.00% (>95%) | Passed web_project | 100/s | 95.37/s (>80.00/s) | 227.71ms | 279.07ms (<750ms) | 100.00% (>95%) | Passed web_project_branches | 100/s | 84.77/s (>48.00/s) | 1997.38ms | 2220.89ms (<1500ms) | 100.00% (>95%) | FAILED³ web_project_commits | 100/s | 95.05/s (>80.00/s) | 389.18ms | 416.96ms (<500ms) | 100.00% (>95%) | Passed web_project_file | 100/s | 60.15/s (>8.00/s) | 1591.69ms | 3304.14ms (<5000ms) | 99.97% (>95%) | Passed web_project_file_blame | 100/s | 5.02/s (>0.80/s) | 15650.74ms | 16389.87ms (<20000ms) | 100.00% (>95%) | Passed web_project_files | 100/s | 68.33/s (>24.00/s) | 664.61ms | 3595.57ms (<4000ms) | 100.00% (>95%) | FAILED³ web_project_issue | 100/s | 95.73/s (>80.00/s) | 310.52ms | 938.52ms (<1500ms) | 100.00% (>95%) | Passed web_project_issues | 100/s | 96.12/s (>80.00/s) | 209.62ms | 271.75ms (<500ms) | 100.00% (>95%) | Passed web_project_merge_request_changes | 100/s | 39.27/s (>40.00/s) | 2687.07ms | 4027.64ms (<4000ms) | 100.00% (>95%) | FAILED³ web_project_merge_request_commits | 100/s | 94.15/s (>48.00/s) | 461.98ms | 706.85ms (<1250ms) | 100.00% (>95%) | Passed web_project_merge_request_discussions | 100/s | 93.5/s (>56.00/s) | 887.81ms | 2309.99ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_requests | 100/s | 96.25/s (>80.00/s) | 243.02ms | 298.91ms (<500ms) | 100.00% (>95%) | Passed web_project_pipelines | 100/s | 95.68/s (>48.00/s) | 282.94ms | 484.07ms (<1000ms) | 100.00% (>95%) | Passed web_search_global | 100/s | 94.88/s (>80.00/s) | 80.57ms | 136.94ms (<1500ms) | 100.00% (>95%) | Passed web_search_groups | 100/s | 95.98/s (>80.00/s) | 72.80ms | 102.84ms (<1000ms) | 100.00% (>95%) | Passed web_search_projects | 100/s | 95.33/s (>80.00/s) | 81.60ms | 277.26ms (<1000ms) | 100.00% (>95%) | Passed web_user | 100/s | 96.32/s (>48.00/s) | 53.48ms | 66.00ms (<4000ms) | 100.00% (>95%) | PassedMetrics (CPU filtered to relevant boxes):

Analysis:
- We have several notable failures, all around Gitaly related test endpoints. This isn't necessarily a shock as we've "downgraded" here from 4 individual Gitaly nodes to 1.
- However with gitlab-org/gitaly#2650 I was expecting this to be better. Looking again at the MRs for distributed reads there may be a config flag I need to set which I'll explore in the next test.
- Looking at the metrics only one Gitaly node appeared to be getting used in this run and that weirdly was
gitaly-3. I would've assumed if there's no distributed reading that the primarygitaly-1should've been getting used. A question for the Gitaly team here. -
api_v4_projects_repository_branchesis notably bad here. It's a known problem endpoint but still this is an increase of 7 seconds.
- Foolishly I've lost the previous 50k metrics for comparison but from knowledge and other environments Postgres usage looks to be higher in places with Praefect is more in use.
- This is also an opportunity to reflect on Postgres's CPU metrics in general. Looking with fresh eyes, with the addition of Praefect on it, it may be worth exploring increasing it's recommended CPU specs at least as it's frequently higher that we'd like across the tests on the larger environments.
Edited by Grant Young- Praefect specs are set to the same as pgbouncer (
Going by the MRs for Distributed Reads it appeared I needed to enable a setting for it to work
praefect['distributed_reads_enabled'] = truebut this hasn't had an effect. The MR was only merged 2 days ago but I would've thought that was enough for it to make it through to nightly.The above could be fundamental for how the new Reference Architectures look in terms of number of clusters so I'm keen to get this on if possible and test it. I suspect with it working the above errors would all be fixed.
As for
gitaly-3getting all the read requests this looks to be perhaps normal. Disabling that node worked as expected and all the request were then funnelled togitaly-2.Edit: turns out the feature was moved to a feature flag - gitlab-org/gitaly!2195
Edited by Grant YoungStill having trouble getting distributed reads to work properly today. Currently discussing with @8bitlife. If the feature doesn't work as expected it looks like the 50k reference architecture will require multiple clusters (and large monorepos may still suffer).
After debugging some more with the Gitaly team it was discovered that the Gitaly nodes weren't in sync and replication jobs were sticking for some reason. As a first step going to try and rebuild the environment to eliminate any potential environmental issues and then continue debugging from there.
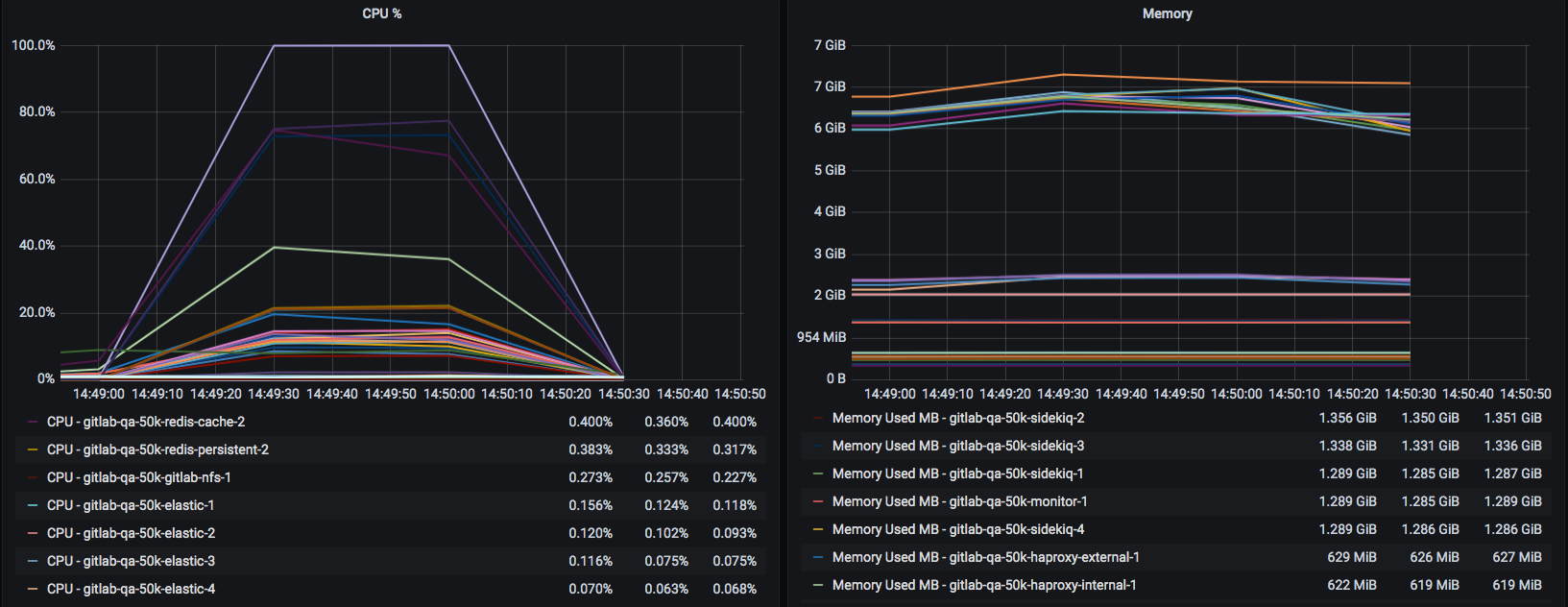
After a rebuild distributed reads looks to be working now. Rerunning the failing tests above showed a good improvement:
█ Results summary * Environment: 50k * Environment Version: 13.0.0-pre `06a6f5a9ae4` * Option: 60s_1000rps * Date: 2020-05-22 * Run Time: 11m 40.27s (Start: 15:11:56 UTC, End: 15:23:37 UTC) * GPT Version: v1.3.1 ❯ Overall Results Score: 40.95% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT -------------------------------------------|--------|----------------------|-----------|---------------------|----------------|------------------ api_v4_projects_repository_branches | 1000/s | 166.75/s (>160.00/s) | 5218.03ms | 6882.09ms (<7500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_sha | 1000/s | 625.9/s (>800.00/s) | 1394.23ms | 2562.30ms (<500ms) | 99.85% (>95%) | FAILED²³ api_v4_projects_repository_compare_commits | 1000/s | 345.52/s (>800.00/s) | 2454.93ms | 4933.97ms (<500ms) | 34.74% (>95%) | FAILED²³ api_v4_projects_repository_files_file | 1000/s | 358.53/s (>800.00/s) | 2420.85ms | 4555.44ms (<500ms) | 99.82% (>95%) | FAILED²³ api_v4_projects_repository_files_file_raw | 1000/s | 281.12/s (>800.00/s) | 2968.24ms | 5948.09ms (<500ms) | 99.56% (>95%) | FAILED²³ api_v4_projects_repository_tree | 1000/s | 665.12/s (>800.00/s) | 1323.19ms | 2414.16ms (<500ms) | 99.92% (>95%) | FAILED²³ web_project_branches | 100/s | 93.88/s (>48.00/s) | 949.61ms | 1111.55ms (<1500ms) | 100.00% (>95%) | Passed web_project_files | 100/s | 84.3/s (>24.00/s) | 366.31ms | 385.31ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_request_changes | 100/s | 64.05/s (>40.00/s) | 1697.26ms | 2226.02ms (<4000ms) | 100.00% (>95%) | PassedMetrics:

- Reads in this setup are focused on the secondaries so we only effectively had 2 nodes being used here so going to add another and test again to get more performance.
- One test
api_v4_projects_repository_compare_commitsposted a lot of 404s weirdly but I suspect this was due to postgres more than Gitaly being maxed out. Unsure if this is due to praefect alone but we may need a spec bump for the database nodes here. Edit - Postgres usage is actually way higher than expected with a doubling of node specs still not being enough, this feels like a bug and will investigate more next week.
Edited by Grant YoungOk yeah after some more testing today there's definitely something up with how Praefect uses it's database when distributed reads are on. Essentially it's database use increases explosively.
To test this I separated out Praefect's database today as a test. When distributed reads are on it's usage increases tenfold:

This was with Postgres running on an 8 core machine. When I had it running against the main database on 50k I saw it max out a 64 core machine (50k typically only requires 16 core).
I tried to find out what queries it was running but this proved to be difficult (any help with this is appreciated).
Regardless this is a blocker for eventually recommending Cluster on the reference architectures and I should probably raise a bug. WDYT @8bitlife?
Edited by Grant Young
I think @jramsay or @zj-gitlab is on duty to decide on it. Thanks for your investigation @grantyoung !
Ah ok great @8bitlife.
One other aspect I was thinking about this is that we don't have PgBouncer in this setup and that could be a factor here as connections aren't pooled.
-
@grantyoung Could you report the RPC/s, split by RPC? On GitLab.com the rate isnt this high, so I think we'll gradually turn this feature on to also understand what does and doesn't work. (RPC/s is about 30 on that cluster)
Edited by Zeger-Jan van de Weg
After speaking with the team further the distributed reads feature is hopefully going to enter beta with 13.1 and then enter GA around 13.3 (although of course this is subject to change).
I strongly believe for the reference architectures and for our customers at the larger end of the scale that distributed reads are a must.
The reason for this is to deliver both true availability of large monorepos as well as performance. Testing has clearly shown that to be performant at this scale distributed reads across multiple gitaly nodes are crucial.
Without distributed reads a customer would need to deploy several large clusters. This will be undesirable due to the complexity and cost implications as well as not being able to deliver true availability of large monorepos. Additionally with distributed reads coming out relatively soon customers will likely want to switch to that and undergo a further configuration change.
As such, my recommendation for the reference architectures and for customers is to wait for distributed reads to be released (at least in Beta for keen customers).
Edited by Grant Young
unassigned @grantyoung
With 13.1 now out the door and Distributed Reads in beta are we ready to do another performance test with it @zj-gitlab @8bitlife?
If there's been no changes though to how Praefect accesses it's database it will be the same as previous. Was there ever an issue raised for this?
-
@grantyoung I think gitlab-org/gitaly#2697 can be used to report if there are any problems with pressure on database.
There were a couple of updates, you can find the full list in gitlab-org&2013 Ok thanks @8bitlife. Sounds like there was nothing done specifically do to the database and how it's accessed? I'll see if I can do another load test on it all soon.

gitlab-org/gitaly#2944 has a link to a query plan when distributed reads were enabled.
Thanks @stanhu, looks like it's still very much an issue. Wasn't aware we were enabling on Production already!
gitlab-org/gitaly#2944 has just been closed (nice one @8bitlife!) so I'll be looking to do another test with this real soon. I'm off next week so it will be the week beginning the 10th or 17th of August.
Edited by Grant YoungUnfortunately we've discovered a new import issue today - gitlab-org/gitlab#235949. This will could block this testing latest until it's fixed but hopefully I can proceed with a slightly older version instead (trying this now).
Edit - Was hoping to get a test done with a slightly older nightly build to avoid the above but still got hit by it. Will be trying with an even older build (but one that will contain the praefect db fix) starting next week.
Edited by Grant Young
mentioned in issue performance#231
marked this issue as related to gitlab-org/gitaly#2944
removed the relation with gitlab-org/gitaly#2944
marked this issue as related to gitlab-org/gitaly#2944

Hey team -- from my discussion with @stanhu the findings here is the same issue with gitlab-org/gitlab#227215 where distributed reads are stalling the whole process.
The good is that we did test it and found an issue, the bad is that the benefit of this finding was not realized in time to prevent gitlab-org/gitlab#227215
I think it would be beneficial to have a mini-retrospective on how we can improve the flow of communication when an imminent performance degradation is about to take place if new features being rolled out.
cc @timzallmann and also @cwoolley-gitlab
-
Also FYI @AnthonySandoval since the retrospective would be created with gitlab-org/gitlab#227215 (comment 376857814) it makes sense to have just one and the same.
Hey @meks. In retrospect I should've just raised an issue and I'm certainly kicking myself I didn't.
Since the feature was unreleased at the time and still under active development I assumed just letting the team know was enough. In addition I didn't know it was to be used in production so soon.
Certainly several learnings for myself here at least moving forward and I'm more than happy to go through a retrospective about how to ensure better communication and actions take place when we (Quality Enablement) find issues for other groups.
removed the relation with performance#246
removed backstage [DEPRECATED] label
assigned to @grantyoung
mentioned in issue gitlab-com/www-gitlab-com#8628 (closed)
marked this issue as related to gitlab-org/gitlab#235949
Gitaly Cluster Performance Test 2 on 50k - Week beginning 2020-08-17
After gitlab-org/gitaly#2944 was fixed and working around gitlab-org/gitlab#235949 testing is restarting on this from today

Focused testing with
api_v4_projects_repository_files_file_rawTest Params:
- Test run is a known Gitaly exerciser -
api_v4_projects_repository_files_file_raw - Tests are run against the 50k environment
- Praefect specs started with being set to the same as pgbouncer (
n1-highcpu-2) unless specified otherwise - Praefect is using the same Postgres database as GitLab
- Distributed reads are on
Test against
13.2.0to confirm previous behavior at 200 RPS* Environment: 50k * Environment Version: 13.2.0-ee `ce28f708ec5` * Option: 60s_200rps * Date: 2020-08-17 * Run Time: 1m 5.97s (Start: 11:08:30 UTC, End: 11:09:36 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 69.22% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|-------|----------------------|-----------|--------------------|----------------|----------------- api_v4_projects_repository_files_file_raw | 200/s | 138.43/s (>160.00/s) | 1303.46ms | 1842.76ms (<500ms) | 100.00% (>95%) | FAILED²
Test against
13.3.0-pre 82d6547b2a5nightly with fix at 200 RPS* Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_200rps * Date: 2020-08-17 * Run Time: 1m 6.11s (Start: 12:15:22 UTC, End: 12:16:28 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 96.99% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|-------|----------------------|----------|-------------------|----------------|---------------- api_v4_projects_repository_files_file_raw | 200/s | 193.97/s (>160.00/s) | 134.03ms | 165.67ms (<500ms) | 100.00% (>95%) | PassedAt the 10k rate here we can see the Postgres performance impact appears to be substantially reduced! Suggesting gitlab-org/gitaly#2944 has indeed been fixed.
Test against
13.3.0-pre 82d6547b2a5nightly with fix at 1000 RPS* Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_1000rps * Date: 2020-08-17 * Run Time: 2m 46.61s (Start: 12:18:35 UTC, End: 12:21:21 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 26.87% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|--------|----------------------|-----------|--------------------|---------------|----------------- api_v4_projects_repository_files_file_raw | 1000/s | 269.95/s (>800.00/s) | 3094.94ms | 5786.45ms (<500ms) | 99.52% (>95%) | FAILED²At the 1000 RPS throughput rate Postgres did get maxed out again though surprisingly. Praefect was also heavily hit and looks to need more specs. Will start to debug it now.
Test against
13.3.0-pre 82d6547b2a5nightly with fix at 1000 RPS and higher Postgres \ Praefect specsTest results were posted here initially that were inaccurate due to Gitaly Cluster distributed reads not working correctly. This is to be followed up separately.
* Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_1000rps * Date: 2020-08-17 * Run Time: 1m 24.11s (Start: 13:48:33 UTC, End: 13:49:57 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 51.3% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|--------|----------------------|-----------|--------------------|---------------|----------------- api_v4_projects_repository_files_file_raw | 1000/s | 513.17/s (>800.00/s) | 1719.65ms | 3677.99ms (<500ms) | 99.96% (>95%) | FAILED²After doubling the specs of Postgres and Praefect (to
n1-standard-32andn1-highcpu-4respectively) the metrics are looking the same as before. Distributed reads again appears to have a very heavy hit on Postgres, even with gitlab-org/gitaly#2944 being fixed.Test against
13.3.0-pre 82d6547b2a5nightly with fix at 1000 RPS and even higher Postgres \ Praefect specs█ Results summary * Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_1000rps * Date: 2020-08-17 * Run Time: 1m 23.65s (Start: 14:31:51 UTC, End: 14:33:15 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 85.35% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|--------|----------------------|----------|-------------------|----------------|----------------- api_v4_projects_repository_files_file_raw | 1000/s | 853.52/s (>800.00/s) | 615.25ms | 998.15ms (<500ms) | 100.00% (>95%) | FAILED²Upped both Postgres and Patroni again to see how they would perform and with
n1-standard-64andn1-highcpu-8respectively we seem to have found some room to breath. Although at this point if this is accurate the need to quadruple Postgres requirements is pretty much a non-starter so at this time it's looking like more improvements need to be made.Full test against
13.3.0-pre 82d6547b2a5nightly with fix at 1000 RPS and even higher Postgres \ Praefect specs* Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_1000rps * Date: 2020-08-17 * Run Time: 1h 14m 42.56s (Start: 15:00:51 UTC, End: 16:15:34 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 93.71% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ---------------------------------------------------------|--------|----------------------|------------|-----------------------|----------------|----------------- api_v4_groups | 1000/s | 974.47/s (>800.00/s) | 63.54ms | 76.24ms (<500ms) | 100.00% (>95%) | Passed api_v4_groups_group | 1000/s | 163.45/s (>80.00/s) | 5328.13ms | 5976.13ms (<7500ms) | 99.42% (>95%) | Passed api_v4_groups_group_subgroups | 1000/s | 977.47/s (>800.00/s) | 70.54ms | 84.51ms (<1500ms) | 100.00% (>95%) | Passed api_v4_groups_projects | 1000/s | 167.62/s (>80.00/s) | 5191.35ms | 5939.66ms (<7000ms) | 100.00% (>95%) | Passed api_v4_projects | 1000/s | 87.97/s (>40.00/s) | 9505.64ms | 11562.72ms (<11000ms) | 100.00% (>95%) | FAILED² api_v4_projects_deploy_keys | 1000/s | 979.42/s (>800.00/s) | 42.94ms | 47.53ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_issues | 1000/s | 594.93/s (>480.00/s) | 1521.92ms | 1854.89ms (<2000ms) | 99.99% (>95%) | Passed api_v4_projects_issues_issue | 1000/s | 522.87/s (>480.00/s) | 1734.28ms | 2147.79ms (<3000ms) | 100.00% (>95%) | Passed api_v4_projects_languages | 1000/s | 978.57/s (>800.00/s) | 40.88ms | 46.06ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests | 1000/s | 759.87/s (>480.00/s) | 1192.07ms | 1457.56ms (<2000ms) | 99.99% (>95%) | Passed api_v4_projects_merge_requests_merge_request | 1000/s | 968.55/s (>800.00/s) | 95.93ms | 109.56ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_changes | 1000/s | 102.3/s (>80.00/s) | 7855.60ms | 10005.56ms (<12000ms) | 99.95% (>95%) | Passed api_v4_projects_merge_requests_merge_request_commits | 1000/s | 971.77/s (>800.00/s) | 65.76ms | 74.65ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_discussions | 1000/s | 850.33/s (>640.00/s) | 1054.12ms | 1283.17ms (<1500ms) | 99.99% (>95%) | Passed api_v4_projects_pagination_keyset | 1000/s | 90.27/s (>40.00/s) | 9261.15ms | 11165.67ms (<11000ms) | 99.94% (>95%) | FAILED² api_v4_projects_project | 1000/s | 973.7/s (>800.00/s) | 110.69ms | 128.71ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_pipelines | 1000/s | 978.77/s (>800.00/s) | 53.30ms | 59.90ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_search_blobs | 1000/s | 929.28/s (>80.00/s) | 390.36ms | 912.17ms (<15000ms) | 100.00% (>95%) | Passed api_v4_projects_project_services | 1000/s | 979.85/s (>800.00/s) | 39.81ms | 43.41ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_branches | 1000/s | 248.73/s (>160.00/s) | 3558.31ms | 4660.77ms (<7500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_branches_branch | 1000/s | 977.02/s (>800.00/s) | 72.37ms | 85.98ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits | 1000/s | 977.85/s (>800.00/s) | 65.49ms | 74.17ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_commit | 1000/s | 974.33/s (>800.00/s) | 116.90ms | 132.29ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_commit_diff | 1000/s | 974.12/s (>800.00/s) | 121.52ms | 138.64ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_compare_commits | 1000/s | 613.42/s (>800.00/s) | 1471.55ms | 2392.53ms (<500ms) | 100.00% (>95%) | FAILED² api_v4_projects_repository_files_file | 1000/s | 565.25/s (>800.00/s) | 226.07ms | 275.51ms (<500ms) | 100.00% (>95%) | FAILED² api_v4_projects_repository_files_file_blame | 1000/s | 75.98/s (>8.00/s) | 10683.91ms | 14261.41ms (<35000ms) | 100.00% (>95%) | Passed api_v4_projects_repository_files_file_raw | 1000/s | 716.08/s (>800.00/s) | 552.69ms | 811.31ms (<500ms) | 100.00% (>95%) | FAILED² api_v4_projects_repository_tree | 1000/s | 975.53/s (>800.00/s) | 102.75ms | 118.60ms (<500ms) | 100.00% (>95%) | Passed api_v4_search_global | 1000/s | 861.9/s (>240.00/s) | 913.52ms | 2124.42ms (<25000ms) | 90.71% (>9.5%) | Passed api_v4_search_groups | 1000/s | 862.43/s (>240.00/s) | 366.57ms | 785.76ms (<25000ms) | 96.54% (>9.5%) | Passed api_v4_search_projects | 1000/s | 891.58/s (>240.00/s) | 1197.06ms | 2402.62ms (<25000ms) | 95.99% (>9.5%) | Passed api_v4_user | 1000/s | 979.33/s (>800.00/s) | 29.74ms | 31.80ms (<500ms) | 100.00% (>95%) | Passed api_v4_users | 1000/s | 980.13/s (>800.00/s) | 36.00ms | 39.22ms (<500ms) | 100.00% (>95%) | Passed git_ls_remote | 100/s | 97.77/s (>80.00/s) | 48.91ms | 50.33ms (<500ms) | 100.00% (>95%) | Passed git_pull | 100/s | 97.9/s (>80.00/s) | 54.83ms | 66.66ms (<500ms) | 100.00% (>95%) | Passed git_push | 100/s | 94.5/s (>80.00/s) | 353.63ms | 613.66ms (<5000ms) | 100.00% (>95%) | Passed scenario_api_new_branches | 10/s | 9.65/s (>8.00/s) | 386.33ms | 417.95ms (<1500ms) | 100.00% (>95%) | Passed scenario_api_new_issues | 10/s | 9.63/s (>8.00/s) | 309.57ms | 737.07ms (<2500ms) | 100.00% (>95%) | Passed web_group | 100/s | 95.33/s (>80.00/s) | 132.82ms | 178.07ms (<500ms) | 100.00% (>95%) | Passed web_project | 100/s | 94.98/s (>80.00/s) | 304.28ms | 358.91ms (<750ms) | 100.00% (>95%) | Passed web_project_branches | 100/s | 94.22/s (>48.00/s) | 645.83ms | 794.60ms (<1500ms) | 100.00% (>95%) | Passed web_project_commit | 100/s | 28.17/s (>16.00/s) | 3039.17ms | 10377.43ms (<12500ms) | 100.00% (>95%) | Passed web_project_commits | 100/s | 94.67/s (>80.00/s) | 456.35ms | 503.96ms (<750ms) | 100.00% (>95%) | Passed web_project_file_blame | 100/s | 25.55/s (>0.80/s) | 3462.05ms | 4098.16ms (<20000ms) | 100.00% (>95%) | Passed web_project_file_rendered | 100/s | 15.95/s (>0.80/s) | 5457.15ms | 12176.07ms (<30000ms) | 100.00% (>95%) | Passed web_project_file_source | 100/s | 48.45/s (>8.00/s) | 1970.79ms | 3935.67ms (<5000ms) | 100.00% (>95%) | Passed web_project_files | 100/s | 96.43/s (>60.00/s) | 176.62ms | 281.01ms (<1000ms) | 100.00% (>95%) | Passed web_project_issue | 100/s | 95.12/s (>80.00/s) | 376.80ms | 1164.56ms (<2000ms) | 100.00% (>95%) | Passed web_project_issues | 100/s | 95.68/s (>80.00/s) | 263.04ms | 331.42ms (<500ms) | 100.00% (>95%) | Passed web_project_merge_request_changes | 100/s | 93.42/s (>40.00/s) | 670.04ms | 1071.16ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_request_commits | 100/s | 93.82/s (>48.00/s) | 539.04ms | 835.46ms (<1250ms) | 100.00% (>95%) | Passed web_project_merge_request_discussions | 100/s | 89.33/s (>56.00/s) | 1097.14ms | 2985.69ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_requests | 100/s | 95.77/s (>80.00/s) | 297.48ms | 359.61ms (<500ms) | 100.00% (>95%) | Passed web_project_pipelines | 100/s | 95.0/s (>48.00/s) | 406.38ms | 687.20ms (<1000ms) | 100.00% (>95%) | Passed web_search_global | 100/s | 94.67/s (>80.00/s) | 93.10ms | 162.13ms (<1500ms) | 100.00% (>95%) | Passed web_search_groups | 100/s | 96.08/s (>80.00/s) | 83.37ms | 127.90ms (<1000ms) | 100.00% (>95%) | Passed web_search_projects | 100/s | 95.48/s (>80.00/s) | 96.56ms | 324.75ms (<1000ms) | 100.00% (>95%) | Passed web_user | 100/s | 96.28/s (>48.00/s) | 63.54ms | 80.22ms (<4000ms) | 100.00% (>95%) | PassedDashboard Snapshot - https://snapshot.raintank.io/dashboard/snapshot/dpfaX6U7J5S67LG2WZS8sNRKTNOEv2Ea?orgId=2
With the full run above only a few tests cause Postgres to spike heavily on a 64 vCPU box. On a 16 vCPU box on my count it would be 9 tests with many others causing postgres to be almost maxed.
While this isn’t like before where Postgres was 100% maxed no matter what specs it was on, this time it looks to require around 4x the recommended machine size (16 to 64 vCPU) compared to what we have on the environment today. This is with Praefect and GitLab using the same database although even if we split it out it would likely be the case that Praefect would need a bigger specced database box than GitLab itself.
I’m open to potentially recommending we up the Postgres specs for the Reference Architectures (I’ve been mulling this on and off for a while but there wasn’t a big enough reason) when we have praefect involved as that’s a good justifiable reason. But quadrupling is way too high and customers won’t accept it I fear. As such there's likely a further issue here to be address with Praefect and Postgres for heavy environments and I'll look to raise one tomorrow to progress further.
Edited by Grant Young- Test run is a known Gitaly exerciser -
Some additional tests to confirm the above:
Full test against
13.3.0-pre 82d6547b2a5nightly with fix at 1000 RPS with postgres only doubled in specsTest was done with a potential new recommendation for Postgres specs on 50k -
n1-standard-32:* Environment: 50k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_1000rps * Date: 2020-08-18 * Run Time: 1h 25m 34.84s (Start: 13:04:12 UTC, End: 14:29:47 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 92.75% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ---------------------------------------------------------|--------|----------------------|------------|-----------------------|----------------|----------------- api_v4_groups | 1000/s | 968.7/s (>800.00/s) | 58.47ms | 64.17ms (<500ms) | 100.00% (>95%) | Passed api_v4_groups_group | 1000/s | 137.88/s (>80.00/s) | 6171.52ms | 9811.58ms (<7500ms) | 98.38% (>95%) | FAILED² api_v4_groups_group_subgroups | 1000/s | 977.77/s (>800.00/s) | 64.95ms | 72.88ms (<1500ms) | 100.00% (>95%) | Passed api_v4_groups_projects | 1000/s | 138.75/s (>80.00/s) | 6122.87ms | 9536.98ms (<7000ms) | 98.77% (>95%) | FAILED² api_v4_projects | 1000/s | 70.95/s (>40.00/s) | 11337.89ms | 15642.28ms (<11000ms) | 98.37% (>95%) | FAILED² api_v4_projects_deploy_keys | 1000/s | 979.2/s (>800.00/s) | 40.89ms | 43.27ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_issues | 1000/s | 701.85/s (>480.00/s) | 1291.27ms | 1584.77ms (<2000ms) | 99.97% (>95%) | Passed api_v4_projects_issues_issue | 1000/s | 793.72/s (>480.00/s) | 1119.67ms | 1731.58ms (<3000ms) | 100.00% (>95%) | Passed api_v4_projects_languages | 1000/s | 977.51/s (>800.00/s) | 39.08ms | 41.57ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests | 1000/s | 875.33/s (>480.00/s) | 999.18ms | 1258.80ms (<2000ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request | 1000/s | 974.8/s (>800.00/s) | 88.96ms | 98.07ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_changes | 1000/s | 107.67/s (>80.00/s) | 7460.39ms | 9571.01ms (<12000ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_commits | 1000/s | 970.08/s (>800.00/s) | 62.30ms | 67.24ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_merge_requests_merge_request_discussions | 1000/s | 959.43/s (>640.00/s) | 351.07ms | 530.19ms (<1500ms) | 99.99% (>95%) | Passed api_v4_projects_pagination_keyset | 1000/s | 70.48/s (>40.00/s) | 11353.89ms | 15450.25ms (<11000ms) | 98.65% (>95%) | FAILED² api_v4_projects_project | 1000/s | 973.7/s (>800.00/s) | 104.33ms | 116.31ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_pipelines | 1000/s | 976.0/s (>800.00/s) | 51.78ms | 55.60ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_project_search_blobs | 1000/s | 895.0/s (>80.00/s) | 394.45ms | 905.98ms (<15000ms) | 100.00% (>95%) | Passed api_v4_projects_project_services | 1000/s | 979.58/s (>800.00/s) | 38.92ms | 41.47ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_branches | 1000/s | 224.2/s (>160.00/s) | 3936.98ms | 5377.21ms (<7500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_branches_branch | 1000/s | 977.27/s (>800.00/s) | 73.01ms | 88.62ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits | 1000/s | 977.8/s (>800.00/s) | 63.30ms | 70.54ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_commit | 1000/s | 973.77/s (>800.00/s) | 118.58ms | 135.41ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_commits_commit_diff | 1000/s | 974.17/s (>800.00/s) | 122.98ms | 140.61ms (<500ms) | 100.00% (>95%) | Passed api_v4_projects_repository_compare_commits | 1000/s | 365.17/s (>800.00/s) | 2420.86ms | 4476.95ms (<500ms) | 99.74% (>95%) | FAILED² api_v4_projects_repository_files_file | 1000/s | 677.73/s (>800.00/s) | 1276.12ms | 2254.65ms (<500ms) | 99.99% (>95%) | FAILED² api_v4_projects_repository_files_file_blame | 1000/s | 81.02/s (>8.00/s) | 10072.27ms | 12540.13ms (<35000ms) | 99.91% (>95%) | Passed api_v4_projects_repository_files_file_raw | 1000/s | 547.75/s (>800.00/s) | 1605.80ms | 3364.28ms (<500ms) | 99.96% (>95%) | FAILED² api_v4_projects_repository_tree | 1000/s | 976.23/s (>800.00/s) | 96.19ms | 113.49ms (<500ms) | 100.00% (>95%) | Passed api_v4_search_global | 1000/s | 772.58/s (>240.00/s) | 2326.73ms | 4485.25ms (<25000ms) | 89.70% (>9.5%) | Passed api_v4_search_groups | 1000/s | 907.37/s (>240.00/s) | 1850.55ms | 3617.01ms (<25000ms) | 67.15% (>9.5%) | Passed api_v4_search_projects | 1000/s | 742.88/s (>240.00/s) | 2468.61ms | 5164.69ms (<25000ms) | 73.65% (>9.5%) | Passed api_v4_user | 1000/s | 979.8/s (>800.00/s) | 29.53ms | 31.79ms (<500ms) | 100.00% (>95%) | Passed api_v4_users | 1000/s | 979.98/s (>800.00/s) | 35.09ms | 37.62ms (<500ms) | 100.00% (>95%) | Passed git_ls_remote | 100/s | 97.73/s (>80.00/s) | 47.95ms | 49.49ms (<500ms) | 100.00% (>95%) | Passed git_pull | 100/s | 97.8/s (>80.00/s) | 54.11ms | 65.58ms (<500ms) | 100.00% (>95%) | Passed git_push | 100/s | 95.77/s (>80.00/s) | 402.07ms | 695.69ms (<5000ms) | 100.00% (>95%) | Passed scenario_api_new_branches | 10/s | 9.48/s (>8.00/s) | 429.84ms | 457.10ms (<1500ms) | 100.00% (>95%) | Passed scenario_api_new_issues | 10/s | 9.58/s (>8.00/s) | 300.59ms | 709.54ms (<2500ms) | 100.00% (>95%) | Passed web_group | 100/s | 94.87/s (>80.00/s) | 130.83ms | 170.91ms (<500ms) | 100.00% (>95%) | Passed web_project | 100/s | 94.77/s (>80.00/s) | 289.05ms | 340.22ms (<750ms) | 100.00% (>95%) | Passed web_project_branches | 100/s | 94.32/s (>48.00/s) | 752.28ms | 979.27ms (<1500ms) | 100.00% (>95%) | Passed web_project_commit | 100/s | 29.82/s (>16.00/s) | 2850.81ms | 9562.01ms (<12500ms) | 100.00% (>95%) | Passed web_project_commits | 100/s | 95.13/s (>80.00/s) | 411.03ms | 469.14ms (<750ms) | 100.00% (>95%) | Passed web_project_file_blame | 100/s | 27.47/s (>0.80/s) | 3230.74ms | 3791.91ms (<20000ms) | 100.00% (>95%) | Passed web_project_file_rendered | 100/s | 17.12/s (>0.80/s) | 5072.10ms | 11012.17ms (<30000ms) | 100.00% (>95%) | Passed web_project_file_source | 100/s | 50.23/s (>8.00/s) | 1872.54ms | 3757.20ms (<5000ms) | 100.00% (>95%) | Passed web_project_files | 100/s | 96.5/s (>60.00/s) | 166.22ms | 252.61ms (<1000ms) | 100.00% (>95%) | Passed web_project_issue | 100/s | 95.48/s (>80.00/s) | 341.86ms | 1000.43ms (<2000ms) | 100.00% (>95%) | Passed web_project_issues | 100/s | 95.83/s (>80.00/s) | 241.06ms | 304.42ms (<500ms) | 100.00% (>95%) | Passed web_project_merge_request_changes | 100/s | 94.6/s (>40.00/s) | 598.18ms | 951.10ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_request_commits | 100/s | 94.8/s (>48.00/s) | 476.38ms | 730.27ms (<1250ms) | 100.00% (>95%) | Passed web_project_merge_request_discussions | 100/s | 92.95/s (>56.00/s) | 962.91ms | 2631.66ms (<4000ms) | 100.00% (>95%) | Passed web_project_merge_requests | 100/s | 95.93/s (>80.00/s) | 280.22ms | 340.39ms (<500ms) | 100.00% (>95%) | Passed web_project_pipelines | 100/s | 94.93/s (>48.00/s) | 376.12ms | 640.39ms (<1000ms) | 100.00% (>95%) | Passed web_search_global | 100/s | 95.07/s (>80.00/s) | 87.51ms | 159.40ms (<1500ms) | 100.00% (>95%) | Passed web_search_groups | 100/s | 95.83/s (>80.00/s) | 78.51ms | 125.10ms (<1000ms) | 100.00% (>95%) | Passed web_search_projects | 100/s | 95.43/s (>80.00/s) | 90.09ms | 311.01ms (<1000ms) | 100.00% (>95%) | Passed web_user | 100/s | 96.35/s (>48.00/s) | 61.83ms | 76.07ms (<4000ms) | 100.00% (>95%) | PassedAs expected several tests failed notably compared to tests done with
n1-standard-64Specific test against
13.3.0-pre 82d6547b2a5on a 10k like environment at 200 RPSPostgres -
n1-standard-4, Praefect -n1-highcpu-4.* Environment: 10k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_200rps * Date: 2020-08-18 * Run Time: 1m 7.14s (Start: 16:14:49 UTC, End: 16:15:56 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 37.1% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|-------|--------------------|-----------|--------------------|----------------|----------------- api_v4_projects_repository_files_file_raw | 200/s | 74.2/s (>160.00/s) | 2407.76ms | 4540.51ms (<500ms) | 100.00% (>95%) | FAILED²Specific test against
13.3.0-pre 82d6547b2a5on a 10k like environment at 200 RPS with doubled Postgres specsPostgres -
n1-standard-8, Praefect -n1-highcpu-4.* Environment: 10k * Environment Version: 13.3.0-pre `82d6547b2a5` * Option: 60s_200rps * Date: 2020-08-18 * Run Time: 1m 6.74s (Start: 16:04:17 UTC, End: 16:05:24 UTC) * GPT Version: v2.0.5 ❯ Overall Results Score: 97.09% NAME | RPS | RPS RESULT | TTFB AVG | TTFB P90 | REQ STATUS | RESULT ------------------------------------------|-------|----------------------|----------|-------------------|----------------|---------------- api_v4_projects_repository_files_file_raw | 200/s | 194.18/s (>160.00/s) | 159.28ms | 204.55ms (<500ms) | 100.00% (>95%) | Passed10k looks to require only a 2x bump to Postgres compared to 4x on 50k.
Edited by Grant YoungI've raised gitlab-org/gitaly#3053 on the back of this testing to get Postgres performance further improved and will test again when done so.
Edited by Grant Young
mentioned in issue gitlab-org/gitaly#3048
marked this issue as related to gitlab-org/gitaly#3048

@derekferguson tagging you to make sure you saw this
mentioned in issue gitlab-org/gitaly#3053
marked this issue as related to gitlab-org/gitaly#3053
marked this issue as related to gitlab-org/gitlab#232692