Update dependency transformers to v4.41.0
This MR contains the following updates:
| Package | Update | Change |
|---|---|---|
| transformers | minor |
==4.40.2 -> ==4.41.0
|
Release Notes
huggingface/transformers (transformers)
v4.41.0: : Phi3, JetMoE, PaliGemma, VideoLlava, Falcon2, FalconVLM & GGUF support
New models
Phi3
The Phi-3 model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
TLDR; Phi-3 introduces new ROPE scaling methods, which seems to scale fairly well! A 3b and a Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.

JetMoE
JetMoe-8B is an 8B Mixture-of-Experts (MoE) language model developed by Yikang Shen and MyShell. JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget. To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the ModuleFormer. Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts. Given the input tokens, it activates a subset of its experts to process them. This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models. The training throughput of JetMoe-8B is around 100B tokens per day on a cluster of 96 H100 GPUs with a straightforward 3-way pipeline parallelism strategy.
- Add JetMoE model by @yikangshen in https://github.com/huggingface/transformers/pull/30005
PaliGemma
PaliGemma is a lightweight open vision-language model (VLM) inspired by PaLI-3, and based on open components like the SigLIP vision model and the Gemma language model. PaliGemma takes both images and text as inputs and can answer questions about images with detail and context, meaning that PaliGemma can perform deeper analysis of images and provide useful insights, such as captioning for images and short videos, object detection, and reading text embedded within images.
More than 120 checkpoints are released see the collection here !
- Add PaliGemma by @molbap in https://github.com/huggingface/transformers/pull/30814
VideoLlava
Video-LLaVA exhibits remarkable interactive capabilities between images and videos, despite the absence of image-video pairs in the dataset.

- Add Video Llava by @zucchini-nlp in https://github.com/huggingface/transformers/pull/29733
Falcon 2 and FalconVLM:
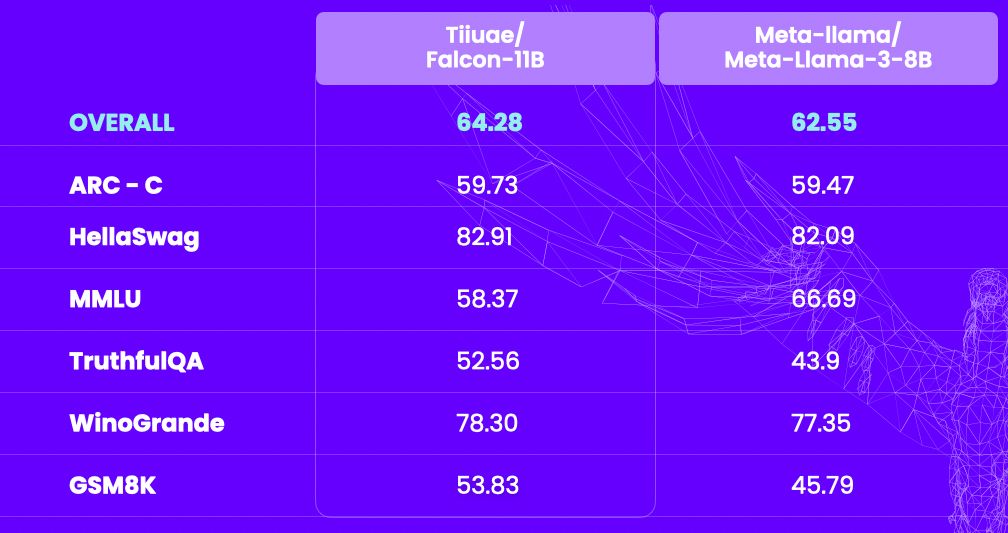
Two new models from TII-UAE! They published a blog-post with more details! Falcon2 introduces parallel mlp, and falcon VLM uses the Llava framework
- Support for Falcon2-11B by @Nilabhra in https://github.com/huggingface/transformers/pull/30771
- Support arbitrary processor by @ArthurZucker in https://github.com/huggingface/transformers/pull/30875
GGUF from_pretrained support

You can now load most of the GGUF quants directly with transformers' from_pretrained to convert it to a classic pytorch model. The API is simple:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)We plan more closer integrations with llama.cpp / GGML ecosystem in the future, see: https://github.com/huggingface/transformers/issues/27712 for more details
- Loading GGUF files support by @LysandreJik in https://github.com/huggingface/transformers/pull/30391
Quantization
New quant methods
In this release we support new quantization methods: HQQ & EETQ contributed by the community. Read more about how to quantize any transformers model using HQQ & EETQ in the dedicated documentation section
- Add HQQ quantization support by @mobicham in https://github.com/huggingface/transformers/pull/29637
- [FEAT]: EETQ quantizer support by @dtlzhuangz in https://github.com/huggingface/transformers/pull/30262
dequantize API for bitsandbytes models
In case you want to dequantize models that have been loaded with bitsandbytes, this is now possible through the dequantize API (e.g. to merge adapter weights)
- FEAT / Bitsandbytes: Add
dequantizeAPI for bitsandbytes quantized models by @younesbelkada in https://github.com/huggingface/transformers/pull/30806
API-wise, you can achieve that with the following:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.dequantize()
text = tokenizer("Hello my name is", return_tensors="pt").to(0)
out = model.generate(**text)
print(tokenizer.decode(out[0]))Generation updates
- Add Watermarking LogitsProcessor and WatermarkDetector by @zucchini-nlp in https://github.com/huggingface/transformers/pull/29676
- Cache: Static cache as a standalone object by @gante in https://github.com/huggingface/transformers/pull/30476
- Make
Gemmawork withtorch.compileby @ydshieh in https://github.com/huggingface/transformers/pull/30775
SDPA support
- [
BERT] Add support for sdpa by @hackyon in https://github.com/huggingface/transformers/pull/28802 - Add sdpa and fa2 the Wav2vec2 family. by @kamilakesbi in https://github.com/huggingface/transformers/pull/30121
- add sdpa to ViT [follow up of #29325] by @hyenal in https://github.com/huggingface/transformers/pull/30555
Improved Object Detection
Addition of fine-tuning script for object detection models
- Fix YOLOS image processor resizing by @qubvel in https://github.com/huggingface/transformers/pull/30436
- Add examples for detection models finetuning by @qubvel in https://github.com/huggingface/transformers/pull/30422
- Add installation of examples requirements in CI by @qubvel in https://github.com/huggingface/transformers/pull/30708
- Update object detection guide by @qubvel in https://github.com/huggingface/transformers/pull/30683
Interpolation of embeddings for vision models
Add interpolation of embeddings. This enables predictions from pretrained models on input images of sizes different than those the model was originally trained on. Simply pass interpolate_pos_embedding=True when calling the model.
Added for: BLIP, BLIP 2, InstructBLIP, SigLIP, ViViT
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
image = Image.open(requests.get("https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg", stream=True).raw)
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
).to("cuda")
inputs = processor(images=image, size={"height": 500, "width": 500}, return_tensors="pt").to("cuda")
predictions = model(**inputs, interpolate_pos_encoding=True)
### Generated text: "a woman and dog on the beach"
generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()- Blip dynamic input resolution by @zafstojano in https://github.com/huggingface/transformers/pull/30722
- Add dynamic resolution input/interpolate position embedding to SigLIP by @davidgxue in https://github.com/huggingface/transformers/pull/30719
- Enable dynamic resolution for vivit by @jla524 in https://github.com/huggingface/transformers/pull/30630
🚨 might be breaking
-
🚨 🚨 🚨 Deprecateevaluation_strategytoeval_strategy🚨 🚨 🚨 by @muellerzr in https://github.com/huggingface/transformers/pull/30190 -
🚨 Add training compatibility for Musicgen-like models by @ylacombe in https://github.com/huggingface/transformers/pull/29802 -
🚨 Update image_processing_vitmatte.py by @rb-synth in https://github.com/huggingface/transformers/pull/30566
Cleanups
- Remove task guides auto-update in favor of links towards task pages by @LysandreJik in https://github.com/huggingface/transformers/pull/30429
- Remove add-new-model in favor of add-new-model-like by @LysandreJik in https://github.com/huggingface/transformers/pull/30424
- Remove mentions of models in the READMEs and link to the documentation page in which they are featured. by @LysandreJik in https://github.com/huggingface/transformers/pull/30420
Not breaking but important for Llama tokenizers
- [
LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881
Fixes
- Fix missing
prev_ci_resultsby @ydshieh in https://github.com/huggingface/transformers/pull/30313 - Fix: remove
pad token idin pipeline forward arguments by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30285 - fix Parameter dtype in audio models by @ylacombe in https://github.com/huggingface/transformers/pull/30310
- disable use_cache if using gradient checkpointing by @chenzizhao in https://github.com/huggingface/transformers/pull/30320
- Fix test transposing image with EXIF Orientation tag by @albertvillanova in https://github.com/huggingface/transformers/pull/30319
- Avoid
jnpimport inutils/generic.pyby @ydshieh in https://github.com/huggingface/transformers/pull/30322 - Fix
AssertionErrorin clip conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30321 - [UDOP] Add special tokens to tokenizer by @NielsRogge in https://github.com/huggingface/transformers/pull/29594
- Enable multi-device for some models by @jla524 in https://github.com/huggingface/transformers/pull/30207
- feat: Upgrade Weights & Biases callback by @parambharat in https://github.com/huggingface/transformers/pull/30135
- [Feature Extractors] Fix kwargs to pre-trained by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/30260
- Pipeline: fix
pad_token_idagain by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30338 - [Whisper] Fix slow tests by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/30152
- parallel job limit for doctest by @ydshieh in https://github.com/huggingface/transformers/pull/30342
- Transformers Metadata by @LysandreJik in https://github.com/huggingface/transformers/pull/30344
- Deprecate default chat templates by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30346
- Restore casting of masked_spec_embed by @ylacombe in https://github.com/huggingface/transformers/pull/30336
- Update unwrap from accelerate by @SunMarc in https://github.com/huggingface/transformers/pull/29933
- Do not remove half seq length in generation tests by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30016
- Fix config + attn_implementation in AutoModelForCausalLM.from_pretrained by @hiyouga in https://github.com/huggingface/transformers/pull/30299
- Add TF swiftformer by @joaocmd in https://github.com/huggingface/transformers/pull/23342
- [Grounding DINO] Add resources by @NielsRogge in https://github.com/huggingface/transformers/pull/30232
- Nits for model docs by @merveenoyan in https://github.com/huggingface/transformers/pull/29795
- Enable multi-device for more models by @jla524 in https://github.com/huggingface/transformers/pull/30379
- GenerationConfig: warn if pad token is negative by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30187
- Add FSDP config for CPU RAM efficient loading through accelerate by @helloworld1 in https://github.com/huggingface/transformers/pull/30002
-
Llamafamily, fixuse_cache=Falsegeneration by @ArthurZucker in https://github.com/huggingface/transformers/pull/30380 - Update docstrings for text generation pipeline by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30343
- Terminator strings for generate() by @Rocketknight1 in https://github.com/huggingface/transformers/pull/28932
- Fix layerwise GaLore optimizer hard to converge with warmup scheduler by @hiyouga in https://github.com/huggingface/transformers/pull/30372
- Jamba: fix left-padding test by @gante in https://github.com/huggingface/transformers/pull/30389
- Fix DETA save_pretrained by @qubvel in https://github.com/huggingface/transformers/pull/30326
- FIX / PEFT: Pass device correctly to peft by @younesbelkada in https://github.com/huggingface/transformers/pull/30397
- [docs] LLM inference by @stevhliu in https://github.com/huggingface/transformers/pull/29791
- show
-rsto show skip reasons by @ArthurZucker in https://github.com/huggingface/transformers/pull/30318 - Add inputs embeds in generation by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30269
- [Grounding DINO] Add support for cross-attention in GroundingDinoMultiHeadAttention by @EduardoPach in https://github.com/huggingface/transformers/pull/30364
- remove redundant logging from longformer by @riklopfer in https://github.com/huggingface/transformers/pull/30365
- fix: link to HF repo/tree/revision when a file is missing by @mapmeld in https://github.com/huggingface/transformers/pull/30406
- [tests] add
require_torch_sdpafor test that needs sdpa support by @faaany in https://github.com/huggingface/transformers/pull/30408 - Jax: scipy version pin by @gante in https://github.com/huggingface/transformers/pull/30402
- Fix on "cache position" for assisted generation by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30068
- fix for itemsize => element_size() for torch backwards compat by @winglian in https://github.com/huggingface/transformers/pull/30133
- Make EosTokenCriteria compatible with mps by @pcuenca in https://github.com/huggingface/transformers/pull/30376
- FIX: re-add bnb on docker image by @younesbelkada in https://github.com/huggingface/transformers/pull/30427
- Fix LayoutLMv2 init issue and doctest by @ydshieh in https://github.com/huggingface/transformers/pull/30278
- Remove old TF port docs by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30426
- Rename torch.run to torchrun by @steven-basart in https://github.com/huggingface/transformers/pull/30405
- Fix use_cache for xla fsdp by @alanwaketan in https://github.com/huggingface/transformers/pull/30353
- [
LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881 - New model MR needs green (slow tests) CI by @ydshieh in https://github.com/huggingface/transformers/pull/30341
- Add llama3 by @ArthurZucker in https://github.com/huggingface/transformers/pull/30334
- [
Llava] + CIs fix red cis and llava integration tests by @ArthurZucker in https://github.com/huggingface/transformers/pull/30440 - [tests] make test device-agnostic by @faaany in https://github.com/huggingface/transformers/pull/30444
- fix uncaught init of linear layer in clip's/siglip's for image classification models by @vasqu in https://github.com/huggingface/transformers/pull/30435
- fix jamba slow foward for multi-gpu by @SunMarc in https://github.com/huggingface/transformers/pull/30418
- [SegGPT] Fix loss calculation by @EduardoPach in https://github.com/huggingface/transformers/pull/30421
- Add
pathsfilter to avoid the chance of being triggered by @ydshieh in https://github.com/huggingface/transformers/pull/30453 - Fix wrong indent in
utils/check_if_new_model_added.pyby @ydshieh in https://github.com/huggingface/transformers/pull/30456 - [
research_project] Most of the security issues come from this requirement.txt by @ArthurZucker in https://github.com/huggingface/transformers/pull/29977 - Neuron: When save_safetensor=False, no need to move model to CPU by @jeffhataws in https://github.com/huggingface/transformers/pull/29703
- Enable fp16 on CPU by @muellerzr in https://github.com/huggingface/transformers/pull/30459
- Non blocking support to torch DL's by @muellerzr in https://github.com/huggingface/transformers/pull/30465
- consistent job / pytest report / artifact name correspondence by @ydshieh in https://github.com/huggingface/transformers/pull/30392
- Workflow / ENH: Add SSH into our runners workflow by @younesbelkada in https://github.com/huggingface/transformers/pull/30425
- FIX / Workflow: Change tailscale trigger condition by @younesbelkada in https://github.com/huggingface/transformers/pull/30471
- FIX / Workflow: Fix SSH workflow bug by @younesbelkada in https://github.com/huggingface/transformers/pull/30474
- [fix codellama conversion] by @ArthurZucker in https://github.com/huggingface/transformers/pull/30472
- Script for finding candidate models for deprecation by @amyeroberts in https://github.com/huggingface/transformers/pull/29686
- Fix SigLip classification doctest by @amyeroberts in https://github.com/huggingface/transformers/pull/30475
- Don't run fp16 MusicGen tests on CPU by @amyeroberts in https://github.com/huggingface/transformers/pull/30466
- Prevent crash with
WandbCallbackwith third parties by @tomaarsen in https://github.com/huggingface/transformers/pull/30477 - Add WSD scheduler by @visheratin in https://github.com/huggingface/transformers/pull/30231
- Fix Issue #29817 Video Classification Task Guide Using Undeclared Variables by @manju-rangam in https://github.com/huggingface/transformers/pull/30457
- Make accelerate install non-torch dependent by @muellerzr in https://github.com/huggingface/transformers/pull/30463
- Introduce Stateful Callbacks by @muellerzr in https://github.com/huggingface/transformers/pull/29666
- Fix Llava for 0-embeddings by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30473
- Do not use deprecated
SourceFileLoader.load_module()in dynamic module loading by @XuehaiPan in https://github.com/huggingface/transformers/pull/30370 - Add sidebar tutorial for chat models by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30401
- Quantization:
HfQuantizerquant method update by @younesbelkada in https://github.com/huggingface/transformers/pull/30484 - [docs] Spanish translation of pipeline_tutorial.md by @aaronjimv in https://github.com/huggingface/transformers/pull/30252
- FEAT: PEFT support for EETQ by @younesbelkada in https://github.com/huggingface/transformers/pull/30449
- Fix the
bitsandbyteserror formatting ("Some modules are dispatched on ...") by @kyo-takano in https://github.com/huggingface/transformers/pull/30494 - Update
dtype_byte_sizeto handle torch.float8_e4m3fn/float8_e5m2 types by @mgoin in https://github.com/huggingface/transformers/pull/30488 - Use the Keras set_random_seed in tests by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30504
- Remove skipping logic now that set_epoch exists by @muellerzr in https://github.com/huggingface/transformers/pull/30501
- [
DETR] Remove timm hardcoded logic in modeling files by @amyeroberts in https://github.com/huggingface/transformers/pull/29038 - [examples] update whisper fine-tuning by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/29938
- Fix GroundingDINO, DPR after BERT SDPA update by @amyeroberts in https://github.com/huggingface/transformers/pull/30506
- load_image - decode b64encode and encodebytes strings by @amyeroberts in https://github.com/huggingface/transformers/pull/30192
- [SegGPT] Fix seggpt image processor by @EduardoPach in https://github.com/huggingface/transformers/pull/29550
- Fix link in dbrx.md by @eitanturok in https://github.com/huggingface/transformers/pull/30509
- Allow boolean FSDP options in fsdp_config by @helloworld1 in https://github.com/huggingface/transformers/pull/30439
- Pass attn_implementation when using AutoXXX.from_config by @amyeroberts in https://github.com/huggingface/transformers/pull/30507
- Fix broken link to Transformers notebooks by @clinty in https://github.com/huggingface/transformers/pull/30512
- Update runner tag for MR slow CI by @ydshieh in https://github.com/huggingface/transformers/pull/30535
- Fix repo. fetch/checkout in MR slow CI job by @ydshieh in https://github.com/huggingface/transformers/pull/30537
- Reenable SDPA's FA2 During Training with torch.compile by @warner-benjamin in https://github.com/huggingface/transformers/pull/30442
- Include safetensors as part of
_load_best_modelby @muellerzr in https://github.com/huggingface/transformers/pull/30553 - Pass
use_cachein kwargs for GPTNeoX by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30538 - Enable multi-device for more models by @jla524 in https://github.com/huggingface/transformers/pull/30409
- Generate: update links on LLM tutorial doc by @gante in https://github.com/huggingface/transformers/pull/30550
- DBRX: make fixup by @gante in https://github.com/huggingface/transformers/pull/30578
- Fix seq2seq collator padding by @vasqu in https://github.com/huggingface/transformers/pull/30556
- BlipModel: get_multimodal_features method by @XavierSpycy in https://github.com/huggingface/transformers/pull/30438
- Add chat templating support for KeyDataset in text-generation pipeline by @DarshanDeshpande in https://github.com/huggingface/transformers/pull/30558
- Fix generation doctests by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30263
- General MR slow CI by @ydshieh in https://github.com/huggingface/transformers/pull/30540
- Remove
use_square_sizeafter loading by @ydshieh in https://github.com/huggingface/transformers/pull/30567 - Use text config's vocab size in testing models by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30568
- Encoder-decoder models: move embedding scale to nn.Module by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30410
- Fix Marian model conversion by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30173
- Refactor default chat template warnings by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30551
- Fix QA example by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30580
- remove jax example by @ArthurZucker in https://github.com/huggingface/transformers/pull/30498
- Fix canonical model --model_type in examples by @amyeroberts in https://github.com/huggingface/transformers/pull/30480
- Gemma: update activation warning by @pcuenca in https://github.com/huggingface/transformers/pull/29995
- Bump gitpython from 3.1.32 to 3.1.41 in /examples/research_projects/decision_transformer by @dependabot in https://github.com/huggingface/transformers/pull/30587
- Fix image segmentation example - don't reopen image by @amyeroberts in https://github.com/huggingface/transformers/pull/30481
- Improve object detection task guideline by @NielsRogge in https://github.com/huggingface/transformers/pull/29967
- Generate: remove deprecated public decoding functions and streamline logic 🧼 by @gante in https://github.com/huggingface/transformers/pull/29956
- Fix llava half precision and autocast issues by @frasermince in https://github.com/huggingface/transformers/pull/29721
- Fix: failing CI after #30568 by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30599
- Fix for Neuron by @michaelbenayoun in https://github.com/huggingface/transformers/pull/30259
- Fix memory leak with CTC training script on Chinese languages by @lucky-bai in https://github.com/huggingface/transformers/pull/30358
- Fix copies for DBRX - neuron fix by @amyeroberts in https://github.com/huggingface/transformers/pull/30610
- fix:missing
output_router_logitsin SwitchTransformers by @lausannel in https://github.com/huggingface/transformers/pull/30573 - Use
contiguous()in clip checkpoint conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30613 - phi3 chat_template does not support system role by @amitportnoy in https://github.com/huggingface/transformers/pull/30606
- Docs: fix
generate-related rendering issues by @gante in https://github.com/huggingface/transformers/pull/30600 - Docs: add missing
StoppingCriteriaautodocs by @gante in https://github.com/huggingface/transformers/pull/30617 - Generate: fix
SinkCacheon Llama models by @gante in https://github.com/huggingface/transformers/pull/30581 - Fix FX tracing issues for Llama by @michaelbenayoun in https://github.com/huggingface/transformers/pull/30619
- Output
Noneas attention when layer is skipped by @jonghwanhyeon in https://github.com/huggingface/transformers/pull/30597 - Fix CI after #30410 by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30612
- add mlp bias for llama models by @mayank31398 in https://github.com/huggingface/transformers/pull/30031
- Fix W&B run name by @qubvel in https://github.com/huggingface/transformers/pull/30462
- HQQ: PEFT support for HQQ by @younesbelkada in https://github.com/huggingface/transformers/pull/30632
- Prevent
TextGenerationPipeline._sanitize_parametersfrom overriding previously provided parameters by @yting27 in https://github.com/huggingface/transformers/pull/30362 - Avoid duplication in MR slow CI model list by @ydshieh in https://github.com/huggingface/transformers/pull/30634
- [
CI update] Try to use dockers and no cache by @ArthurZucker in https://github.com/huggingface/transformers/pull/29202 - Check if the current compiled version of pytorch supports MPS by @jiaqianjing in https://github.com/huggingface/transformers/pull/30664
- Hotfix-change-ci by @ArthurZucker in https://github.com/huggingface/transformers/pull/30669
- Quantization / HQQ: Fix HQQ tests on our runner by @younesbelkada in https://github.com/huggingface/transformers/pull/30668
- Fix llava next tie_word_embeddings config by @SunMarc in https://github.com/huggingface/transformers/pull/30640
- Trainer._load_from_checkpoint - support loading multiple Peft adapters by @claralp in https://github.com/huggingface/transformers/pull/30505
- Trainer - add cache clearing and the option for batched eval metrics computation by @FoamoftheSea in https://github.com/huggingface/transformers/pull/28769
- Fix typo: llama3.md by @mimbres in https://github.com/huggingface/transformers/pull/30653
- Respect
resume_downloaddeprecation by @Wauplin in https://github.com/huggingface/transformers/pull/30620 - top-k instead of top-p in MixtralConfig docstring by @sorgfresser in https://github.com/huggingface/transformers/pull/30687
- Bump jinja2 from 3.1.3 to 3.1.4 in /examples/research_projects/decision_transformer by @dependabot in https://github.com/huggingface/transformers/pull/30680
- Bump werkzeug from 3.0.1 to 3.0.3 in /examples/research_projects/decision_transformer by @dependabot in https://github.com/huggingface/transformers/pull/30679
- Adding _tie_weights() to prediction heads to support low_cpu_mem_usage=True by @hackyon in https://github.com/huggingface/transformers/pull/29024
- Fix
cache_positioninitialisation for generation withuse_cache=Falseby @nurlanov-zh in https://github.com/huggingface/transformers/pull/30485 - Word-level timestamps broken for short-form audio by @kamilakesbi in https://github.com/huggingface/transformers/pull/30325
- Updated docs of
forwardinIdefics2ForConditionalGenerationwith correctignore_indexvalue by @zafstojano in https://github.com/huggingface/transformers/pull/30678 - Bump tqdm from 4.63.0 to 4.66.3 in /examples/research_projects/decision_transformer by @dependabot in https://github.com/huggingface/transformers/pull/30646
- Bump tqdm from 4.48.2 to 4.66.3 in /examples/research_projects/visual_bert by @dependabot in https://github.com/huggingface/transformers/pull/30645
- Reboot Agents by @aymeric-roucher in https://github.com/huggingface/transformers/pull/30387
- Bump tqdm from 4.48.2 to 4.66.3 in /examples/research_projects/lxmert by @dependabot in https://github.com/huggingface/transformers/pull/30644
- Separate tokenizer tests by @ArthurZucker in https://github.com/huggingface/transformers/pull/30675
- Update
workflow_idinutils/get_previous_daily_ci.pyby @ydshieh in https://github.com/huggingface/transformers/pull/30695 - Rename artifact name
prev_ci_resultstoci_resultsby @ydshieh in https://github.com/huggingface/transformers/pull/30697 - Add safetensors to model not found error msg for default use_safetensors value by @davidgxue in https://github.com/huggingface/transformers/pull/30602
- Pin deepspeed by @muellerzr in https://github.com/huggingface/transformers/pull/30701
- Patch CLIP image preprocessor by @rootonchair in https://github.com/huggingface/transformers/pull/30698
- [BitsandBytes] Verify if GPU is available by @NielsRogge in https://github.com/huggingface/transformers/pull/30533
- Llava: remove dummy labels by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30706
- Immutability for data collators by @vasqu in https://github.com/huggingface/transformers/pull/30603
- Cache: models return input cache type by @gante in https://github.com/huggingface/transformers/pull/30716
- Removal of deprecated maps by @LysandreJik in https://github.com/huggingface/transformers/pull/30576
- Generate: add
min_psampling by @gante in https://github.com/huggingface/transformers/pull/30639 - Fix image post-processing for OWLv2 by @jla524 in https://github.com/huggingface/transformers/pull/30686
- KV cache is no longer a model attribute by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30730
- Generate: consistently handle special tokens as tensors by @gante in https://github.com/huggingface/transformers/pull/30624
- Update CodeLlama references by @osanseviero in https://github.com/huggingface/transformers/pull/30218
- [docs] Update es/pipeline_tutorial.md by @aaronjimv in https://github.com/huggingface/transformers/pull/30684
- Update llama3.md, fix typo by @mimbres in https://github.com/huggingface/transformers/pull/30739
- mlp_only_layers is more flexible than decoder_sparse_step by @eigen2017 in https://github.com/huggingface/transformers/pull/30552
- PEFT / Trainer: Make use of
model.active_adapters()instead of deprecatedmodel.active_adapterwhenever possible by @younesbelkada in https://github.com/huggingface/transformers/pull/30738 - [docs] Update link in es/pipeline_webserver.md by @aaronjimv in https://github.com/huggingface/transformers/pull/30745
- hqq - fix weight check in check_quantized_param by @mobicham in https://github.com/huggingface/transformers/pull/30748
- [awq] replace scale when we have GELU by @SunMarc in https://github.com/huggingface/transformers/pull/30074
- Workflow: Replace
actions/post-slackwith centrally defined workflow by @younesbelkada in https://github.com/huggingface/transformers/pull/30737 - [GroundingDino] Adding ms_deform_attn kernels by @EduardoPach in https://github.com/huggingface/transformers/pull/30768
- Llama: fix custom 4D masks, v2 by @poedator in https://github.com/huggingface/transformers/pull/30348
- Generation / FIX: Fix multi-device generation by @younesbelkada in https://github.com/huggingface/transformers/pull/30746
- Qwen: incorrect setup flag by @gante in https://github.com/huggingface/transformers/pull/30776
- enable Pipeline to get device from model by @faaany in https://github.com/huggingface/transformers/pull/30534
- [Object detection pipeline] Lower threshold by @NielsRogge in https://github.com/huggingface/transformers/pull/30710
- Generate: remove near-duplicate sample/greedy copy by @gante in https://github.com/huggingface/transformers/pull/30773
- Port IDEFICS to tensorflow by @a8nova in https://github.com/huggingface/transformers/pull/26870
- Generate: assistant should be greedy in assisted decoding by @gante in https://github.com/huggingface/transformers/pull/30778
- Save other CI jobs' result (torch/tf pipeline, example, deepspeed etc) by @ydshieh in https://github.com/huggingface/transformers/pull/30699
- Deprecate models script by @amyeroberts in https://github.com/huggingface/transformers/pull/30184
- skip low_cpu_mem_usage tests by @SunMarc in https://github.com/huggingface/transformers/pull/30782
- CI: update to ROCm 6.0.2 and test MI300 by @fxmarty in https://github.com/huggingface/transformers/pull/30266
- Fix OWLv2 Doc by @jla524 in https://github.com/huggingface/transformers/pull/30794
- Fix cache type in Idefics2 by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30729
- PEFT: Access active_adapters as a property in Trainer by @pashminacameron in https://github.com/huggingface/transformers/pull/30790
- CI: more models wo cache support by @gante in https://github.com/huggingface/transformers/pull/30780
- Deprecate TF weight conversion since we have full Safetensors support now by @Rocketknight1 in https://github.com/huggingface/transformers/pull/30786
- [T5] Adding
model_parallel = FalsetoT5ForTokenClassificationandMT5ForTokenClassificationby @retarfi in https://github.com/huggingface/transformers/pull/30763 - Added the necessay import of module by @ankur0904 in https://github.com/huggingface/transformers/pull/30804
- Add support for custom checkpoints in MusicGen by @jla524 in https://github.com/huggingface/transformers/pull/30011
- Add missing dependencies in image classification example by @jla524 in https://github.com/huggingface/transformers/pull/30820
- Support mixed-language batches in
WhisperGenerationMixinby @cifkao in https://github.com/huggingface/transformers/pull/29688 - Remove unused module DETR based models by @conditionedstimulus in https://github.com/huggingface/transformers/pull/30823
- Jamba - Skip 4d custom attention mask test by @amyeroberts in https://github.com/huggingface/transformers/pull/30826
- Missing
Optionalin typing. by @xkszltl in https://github.com/huggingface/transformers/pull/30821 - Update ds_config_zero3.json by @pacman100 in https://github.com/huggingface/transformers/pull/30829
- Better llava next. by @nxphi47 in https://github.com/huggingface/transformers/pull/29850
- Deprecate models script - correctly set the model name for the doc file by @amyeroberts in https://github.com/huggingface/transformers/pull/30785
- Use
torch 2.3for CI by @ydshieh in https://github.com/huggingface/transformers/pull/30837 - Fix llama model sdpa attention forward function masking bug when output_attentions=True by @Aladoro in https://github.com/huggingface/transformers/pull/30652
- [LLaVa-NeXT] Small fixes by @NielsRogge in https://github.com/huggingface/transformers/pull/30841
- [Idefics2] Improve docs, add resources by @NielsRogge in https://github.com/huggingface/transformers/pull/30717
- Cache: add new flag to distinguish models that
Cachebut not static cache by @gante in https://github.com/huggingface/transformers/pull/30800 - Disable the FA backend for SDPA on AMD GPUs by @mht-sharma in https://github.com/huggingface/transformers/pull/30850
- Video-LLaVa: Fix docs by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30855
- Docs: update example with assisted generation + sample by @gante in https://github.com/huggingface/transformers/pull/30853
- TST / Quantization: Reverting to torch==2.2.1 by @younesbelkada in https://github.com/huggingface/transformers/pull/30866
- Fix VideoLlava imports by @amyeroberts in https://github.com/huggingface/transformers/pull/30867
- TEST: Add llama logits tests by @younesbelkada in https://github.com/huggingface/transformers/pull/30835
- Remove deprecated logic and warnings by @amyeroberts in https://github.com/huggingface/transformers/pull/30743
- Enable device map by @darshana1406 in https://github.com/huggingface/transformers/pull/30870
- Fix dependencies for image classification example by @jla524 in https://github.com/huggingface/transformers/pull/30842
- [whisper] fix multilingual fine-tuning by @sanchit-gandhi in https://github.com/huggingface/transformers/pull/30865
- update release script by @ArthurZucker in https://github.com/huggingface/transformers/pull/30880
New Contributors
- @joaocmd made their first contribution in https://github.com/huggingface/transformers/pull/23342
- @kamilakesbi made their first contribution in https://github.com/huggingface/transformers/pull/30121
- @dtlzhuangz made their first contribution in https://github.com/huggingface/transformers/pull/30262
- @steven-basart made their first contribution in https://github.com/huggingface/transformers/pull/30405
- @manju-rangam made their first contribution in https://github.com/huggingface/transformers/pull/30457
- @kyo-takano made their first contribution in https://github.com/huggingface/transformers/pull/30494
- @mgoin made their first contribution in https://github.com/huggingface/transformers/pull/30488
- @eitanturok made their first contribution in https://github.com/huggingface/transformers/pull/30509
- @clinty made their first contribution in https://github.com/huggingface/transformers/pull/30512
- @warner-benjamin made their first contribution in https://github.com/huggingface/transformers/pull/30442
- @XavierSpycy made their first contribution in https://github.com/huggingface/transformers/pull/30438
- @DarshanDeshpande made their first contribution in https://github.com/huggingface/transformers/pull/30558
- @frasermince made their first contribution in https://github.com/huggingface/transformers/pull/29721
- @lucky-bai made their first contribution in https://github.com/huggingface/transformers/pull/30358
- @rb-synth made their first contribution in https://github.com/huggingface/transformers/pull/30566
- @lausannel made their first contribution in https://github.com/huggingface/transformers/pull/30573
- @jonghwanhyeon made their first contribution in https://github.com/huggingface/transformers/pull/30597
- @mobicham made their first contribution in https://github.com/huggingface/transformers/pull/29637
- @yting27 made their first contribution in https://github.com/huggingface/transformers/pull/30362
- @jiaqianjing made their first contribution in https://github.com/huggingface/transformers/pull/30664
- @claralp made their first contribution in https://github.com/huggingface/transformers/pull/30505
- @mimbres made their first contribution in https://github.com/huggingface/transformers/pull/30653
- @sorgfresser made their first contribution in https://github.com/huggingface/transformers/pull/30687
- @nurlanov-zh made their first contribution in https://github.com/huggingface/transformers/pull/30485
- @zafstojano made their first contribution in https://github.com/huggingface/transformers/pull/30678
- @davidgxue made their first contribution in https://github.com/huggingface/transformers/pull/30602
- @rootonchair made their first contribution in https://github.com/huggingface/transformers/pull/30698
- @eigen2017 made their first contribution in https://github.com/huggingface/transformers/pull/30552
- @Nilabhra made their first contribution in https://github.com/huggingface/transformers/pull/30771
- @a8nova made their first contribution in https://github.com/huggingface/transformers/pull/26870
- @pashminacameron made their first contribution in https://github.com/huggingface/transformers/pull/30790
- @retarfi made their first contribution in https://github.com/huggingface/transformers/pull/30763
- @yikangshen made their first contribution in https://github.com/huggingface/transformers/pull/30005
- @ankur0904 made their first contribution in https://github.com/huggingface/transformers/pull/30804
- @conditionedstimulus made their first contribution in https://github.com/huggingface/transformers/pull/30823
- @nxphi47 made their first contribution in https://github.com/huggingface/transformers/pull/29850
- @Aladoro made their first contribution in https://github.com/huggingface/transformers/pull/30652
- @hyenal made their first contribution in https://github.com/huggingface/transformers/pull/30555
- @darshana1406 made their first contribution in https://github.com/huggingface/transformers/pull/30870
Full Changelog: https://github.com/huggingface/transformers/compare/v4.40.2...v4.41.0
Configuration
-
If you want to rebase/retry this MR, check this box
This MR has been generated by Renovate Bot.